Incremetal update
2 minute read
When it comes to incremental updates, the two previous approaches seem to take completely opposite paths.
GraphRAG uses a three-layer Leiden algorithm to abstract the original homogeneous knowledge graph across multiple levels. One major downside of the Leiden algorithm is that adding even a few new nodes can totally disrupt the existing community structure. In other words, trying to update the graph can force you to recompute an entirely new set of communities and summaries at all three levels. Sure, there are ways to mitigate this issue, but they often add significant complexity—and waste precious compute resources.
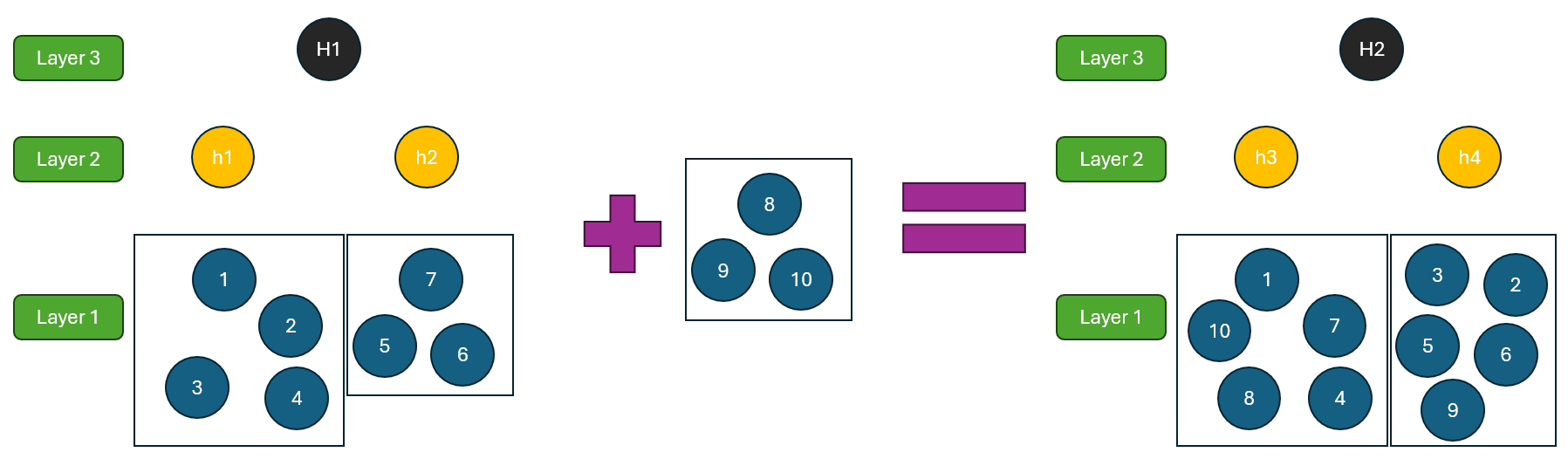
Figure 1. GraphRAG’s community structure — powerful, but hard to update efficiently
On the other hand, LightRAG takes a much simpler approach. It skips the whole graph summary idea and instead relies on paragraph-level structure, using extracted keywords as retrieval indices. This drastically cuts down on processing time and complexity—but it also means losing the rich corpus-level information enhancement that GraphRAG provides.
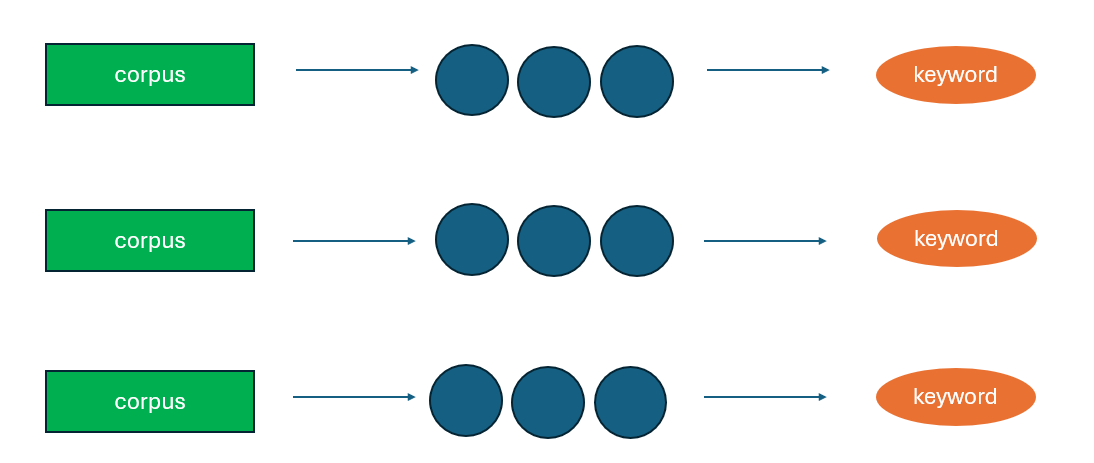
Figure 2. LightRAG simplifies things by relying on keywords, but sacrifices context-rich graph summaries
NodeRAG aims to strike a balance by combining the strengths of both approaches, leveraging the power of heterogeneous graphs. First, it uses only one layer of the Leiden algorithm to identify high-level information within communities—avoiding the three-layer complexity altogether. Second, thanks to its shallow PPR algorithm on heterogeneous graphs, new nodes can be directly merged into the existing graph. This ensures that semantically similar high-dimensional nodes remain close in graph space, while shallow PPR helps surface the most relevant nodes during retrieval.
Let’s walk through an example. Suppose we have a community centered around Concept A (represented as a high-level node connected to lower-level nodes in the heterogeneous graph). This community was built when indexing the original corpus. Now, we add new data. NodeRAG builds a new heterogeneous graph for the fresh corpus—say it forms a new Concept B community. NodeRAG then automatically merges the new and old graphs. Since some lower-level nodes are shared, Concept A’s and Concept B’s communities become interlinked. During retrieval, when a user query activates nodes under Concept A, the shallow PPR algorithm propagates through the graph, potentially reaching and highlighting Concept B—especially if some of its nodes were also relevant entry points.
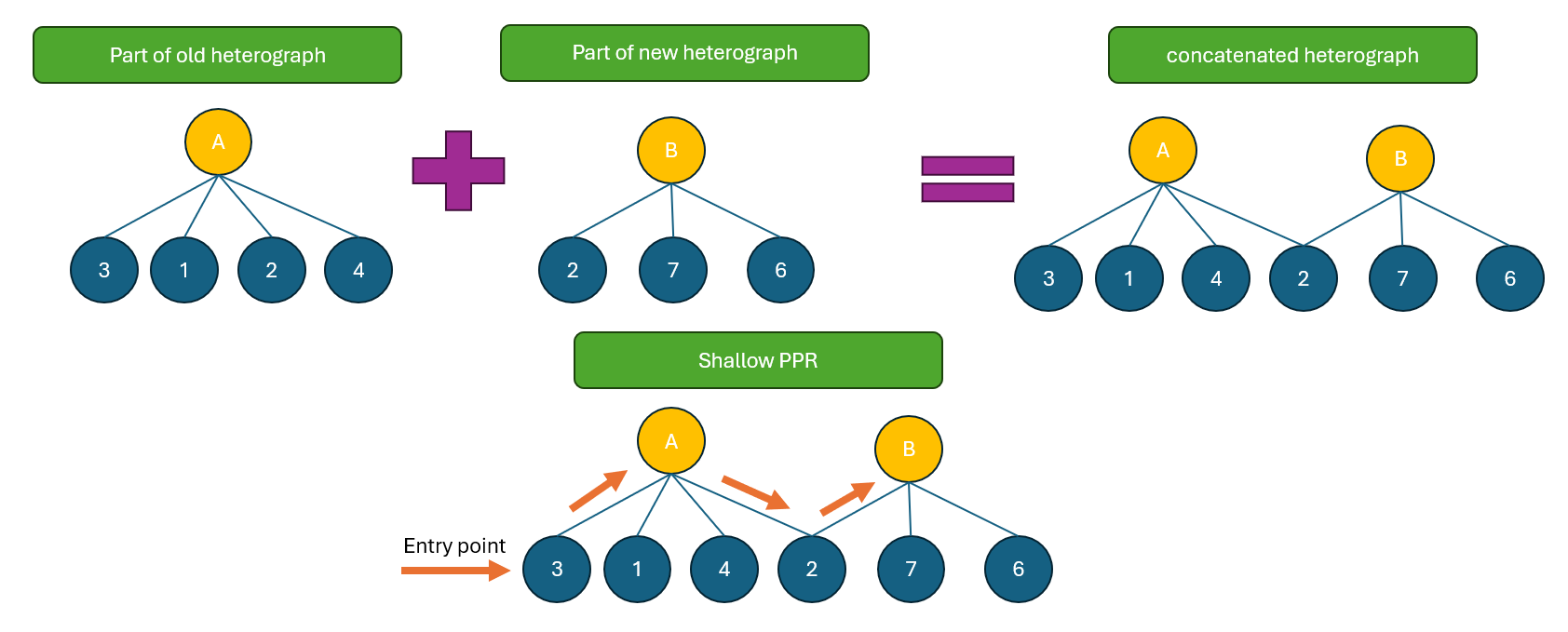
Figure 3. NodeRAG merges new and old graphs seamlessly, enabling efficient and context-aware updates