This is the multi-page printable view of this section. Click here to print.
Indexing
- 1: Build
- 2: Increment Update
1 - Build
Build
Get familiar with project construction
The NodeRAG project has the following structure. You need to manually construct this structure by creating a project folder and placing the input folder inside it. In the input folder, place the corpus you need to RAG.
main_folder/
├── input/
│ ├── file1.md
│ ├── file2.txt
│ ├── file3.docx
│ └── ...
Key Directories
- main_folder: The root directory of the project.
- input: Contains all input files to be processed by NodeRAG. Supported file formats include:
.md,.doc, and.txt.
Quick Input Example
Download this txt file as a quick example to your input folder.
Config
python -m NodeRAG.build -f path/to/main_foulder
When you first use this command, it will create Node_config.yaml file in the main_folder directory.

Modify the config file according to the following instructions (add API and service provider) to ensure that NodeRAG can access the correct API.
To quickly use the NodeRAG demo, set the API key for your OpenAI account. If you don’t have an API key, refer to the OpenAI Auth. Ensure you enter the API key in both the model_config and embedding_config sections.
For detailed configuration and modification instructions, see the Configuration Guide.
#==============================================================================
# AI Model Configuration
#==============================================================================
model_config:
model_name: gpt-4o-mini # Model name for text generation
api_keys: # Your API key (optional)
embedding_config:
api_keys: # Your API key (optional)
Building
After setting up the config, rerun the following command:
python -m NodeRAG.build -f path/to/main_folder
The terminal will display the state tree:
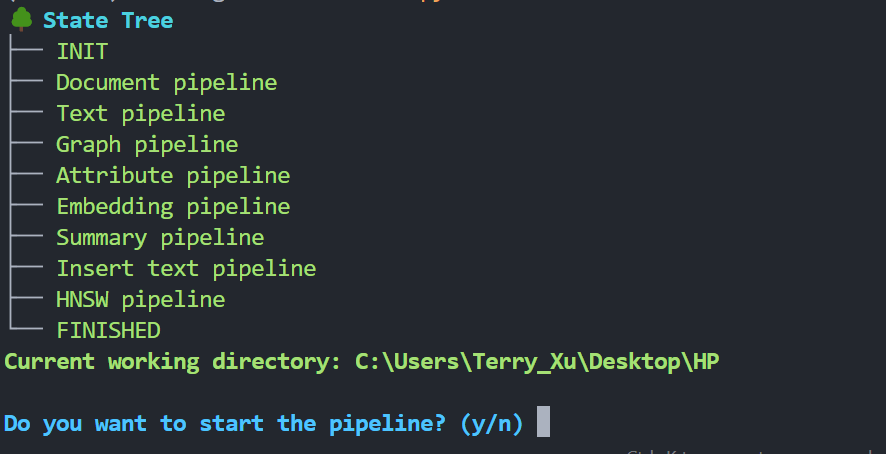
Press y to continue. Wait for the workflow to complete.

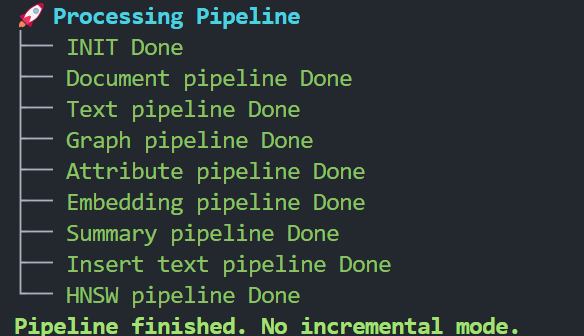
The indexing process will then finish. The final structure (after generation) will be explained in the NodeRAG file structures documentation.
For the next step, see the Answer documentation to generate domain-specific answers.
2 - Increment Update
Incremental Update Support
NodeRAG supports incremental updates. It tracks the hash IDs of previously indexed documents to manage updates efficiently.
Do not modify files that have already been indexed, as this may lead to duplicate indexing or unpredictable errors.
Best Practice for Adding New Corpus
To add new documents, place the new files in the input folder, then rerun the indexing command:
python -m NodeRAG.build -f path/to/main_folder
NodeRAG will automatically detect new files and convert them into its internal database format without reprocessing existing data.
For more details on incremental mode and a comparison between GraphRAG and LightRAG approaches to incremental updates, see this blog post.