This is the multi-page printable view of this section. Click here to print.
博客
结构化输出
结构化输出在NodeRAG中的挑战
NodeRAG高度依赖于将长文本分解为结构化提示以进行进一步处理。具体来说,它依赖于从较长文本输入中持续生成结构化JSON输出的能力。一方面,我们需要系统在复杂、延伸的任务中保持适当的格式。为实现这一点,我们的项目最初依赖于OpenAI的结构化输出功能(文档在此)。借此,模型可靠地将文本块分解为异构节点,使下游处理变得顺畅高效。
然而,当我们尝试扩展到其他模型时,遇到了一些障碍。例如,OpenAI的结构输出失败(即输出不遵循预期的JSON格式)发生率不到1%——相当稳定。但当我们尝试Gemini 2.0 Flash时,这一失败率跃升至约20%。更糟的是,使用DeepSeek的官方JSON输出时,近60%的API响应忽略了规定的格式,这使得错误处理几乎不可能。
由于这些问题,在v0.1.0版本中,我们仅支持OpenAI和Gemini用于结构化输出任务。
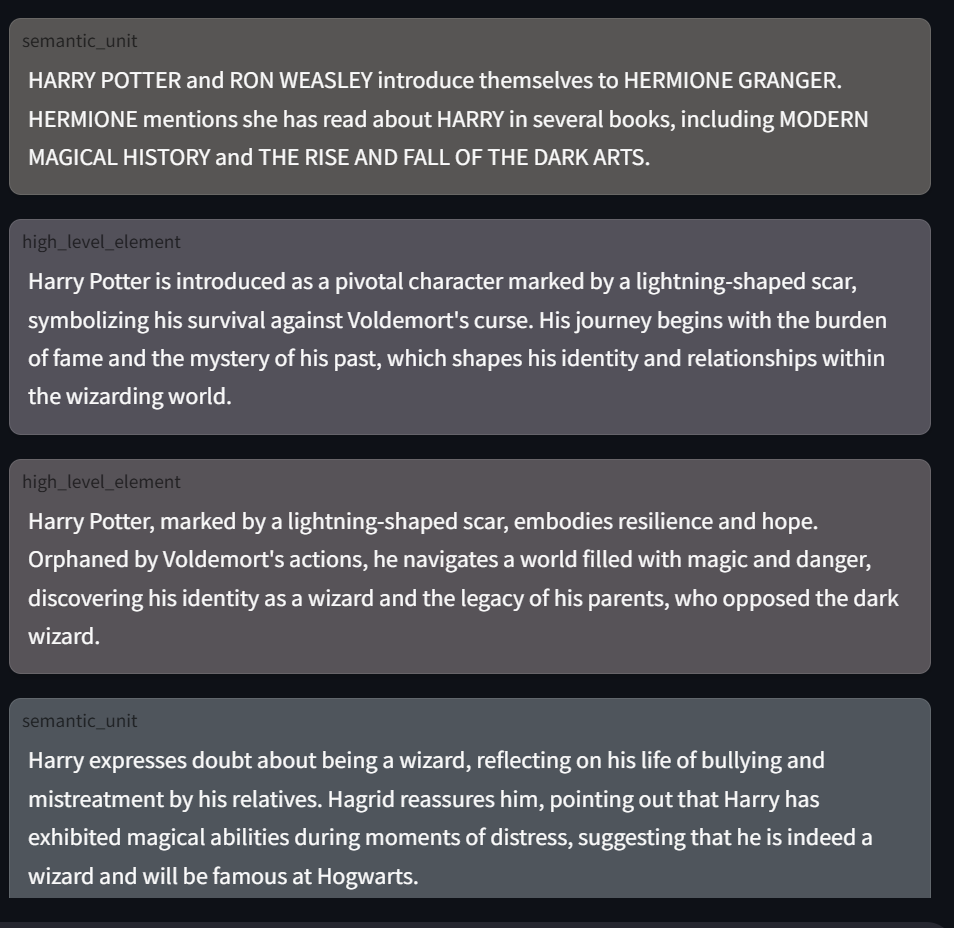
图1. OpenAI GPT-4o-mini — 高度可靠的JSON输出

图2. Gemini 2.0 Flash — 可接受的格式,但内容质量较低
话虽如此,尽管Gemini比DeepSeek更常能坚持格式,我们注意到其输出的质量存在问题——例如重复短语、多余空格,以及与OpenAI的GPT-4o-mini相比整体保真度较低的内容。
我们的建议
到目前为止,我们建议在NodeRAG中使用OpenAI的模型,特别是对于需要一致结构化输出的任务。我们将继续评估其他模型的结构化输出能力,看它们是否最终能适应NodeRAG流程。
展望未来
我们对未来一个令人兴奋的方向是:专门为NodeRAG文本到节点分解步骤进行微调轻量级模型。这项任务本质上是摘要和改述的混合,所以相对直接。挑战在于在长文本输入上保持稳定的结构化输出。
一旦文本被分解为结构化节点,我们可以使用更强大的模型从图中提取更高层次的见解和观点总结。
增量更新
在谈到增量更新时,之前的两种方法似乎采取了完全相反的路径。
GraphRAG使用三层Leiden算法在多个层次上抽象原始的同质知识图。Leiden算法的一个主要缺点是,即使只添加几个新节点也可能完全扰乱现有的社区结构。换句话说,尝试更新图可能会迫使你在所有三个层次上重新计算一套全新的社区和摘要。当然,有一些方法可以缓解这个问题,但它们通常会增加显著的复杂性——并浪费宝贵的计算资源。
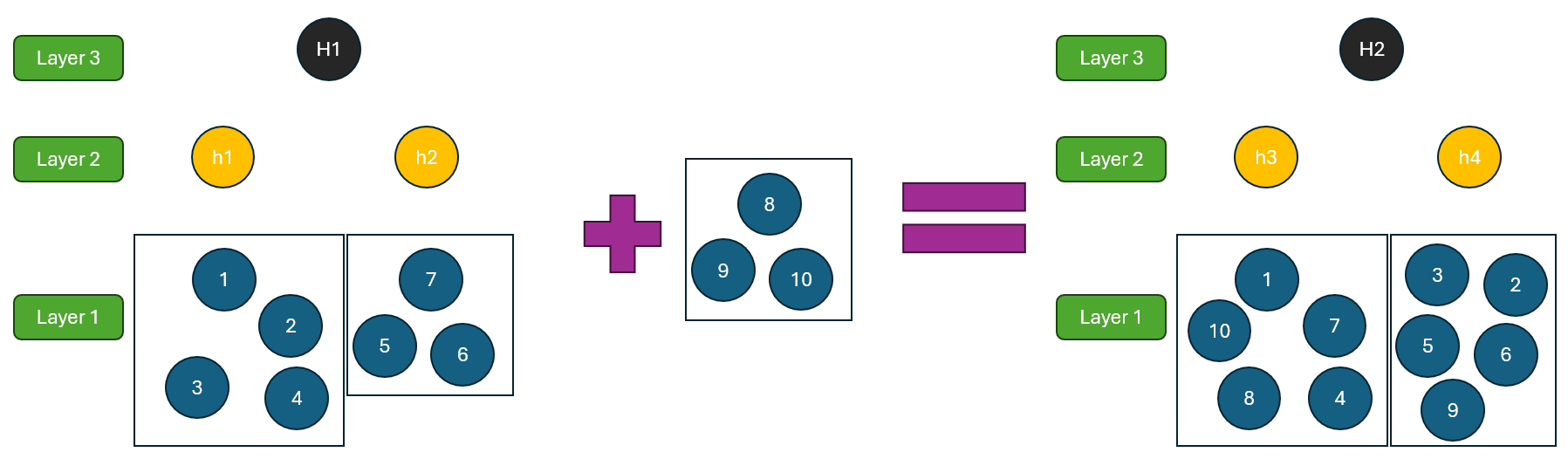
图1. GraphRAG的社区结构——功能强大,但难以高效更新
另一方面,LightRAG采取了一种简单得多的方法。它跳过了整个图摘要的想法,而是依赖于段落级别的结构,使用提取的关键词作为检索索引。这大大减少了处理时间和复杂性——但也意味着失去了GraphRAG提供的丰富的语料级信息增强。
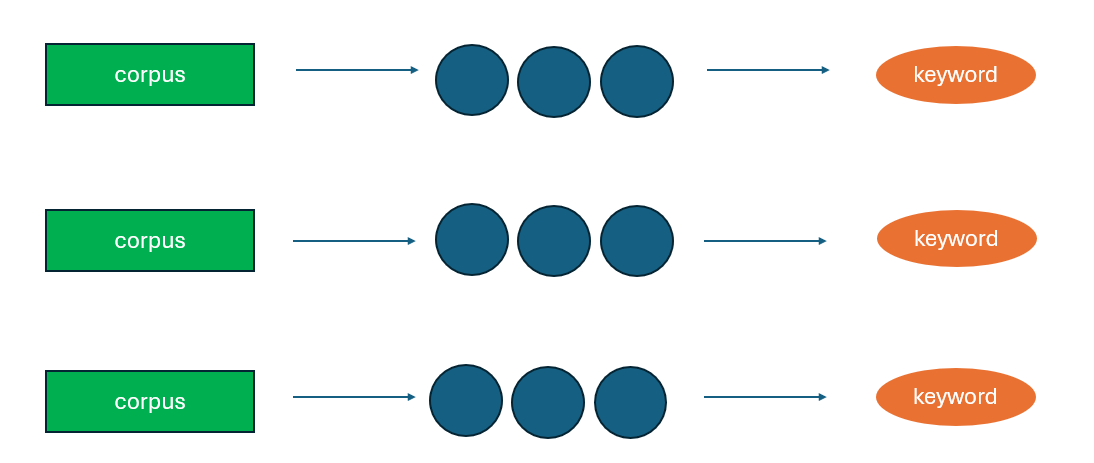
图2. LightRAG通过依赖关键词简化了流程,但牺牲了上下文丰富的图摘要
NodeRAG旨在通过结合两种方法的优势,利用异质图的力量来取得平衡。首先,它仅使用Leiden算法的一层来识别社区内的高级信息——完全避开了三层复杂性。其次,得益于其在异质图上的浅层PPR算法,新节点可以直接合并到现有图中。这确保了语义相似的高维节点在图空间中保持接近,同时浅层PPR在检索期间帮助浮现最相关的节点。
让我们通过一个例子来说明。假设我们有一个以概念A为中心的社区(在异质图中表示为一个连接到较低级别节点的高级节点)。这个社区是在索引原始语料库时建立的。现在,我们添加新数据。NodeRAG为新语料库构建一个新的异质图——假设它形成了一个新的概念B社区。然后,NodeRAG自动合并新旧图。由于一些低级节点是共享的,概念A和概念B的社区变得相互关联。在检索过程中,当用户查询激活概念A下的节点时,浅层PPR算法在图中传播,可能会到达并突出概念B——特别是如果它的一些节点也是相关的入口点。
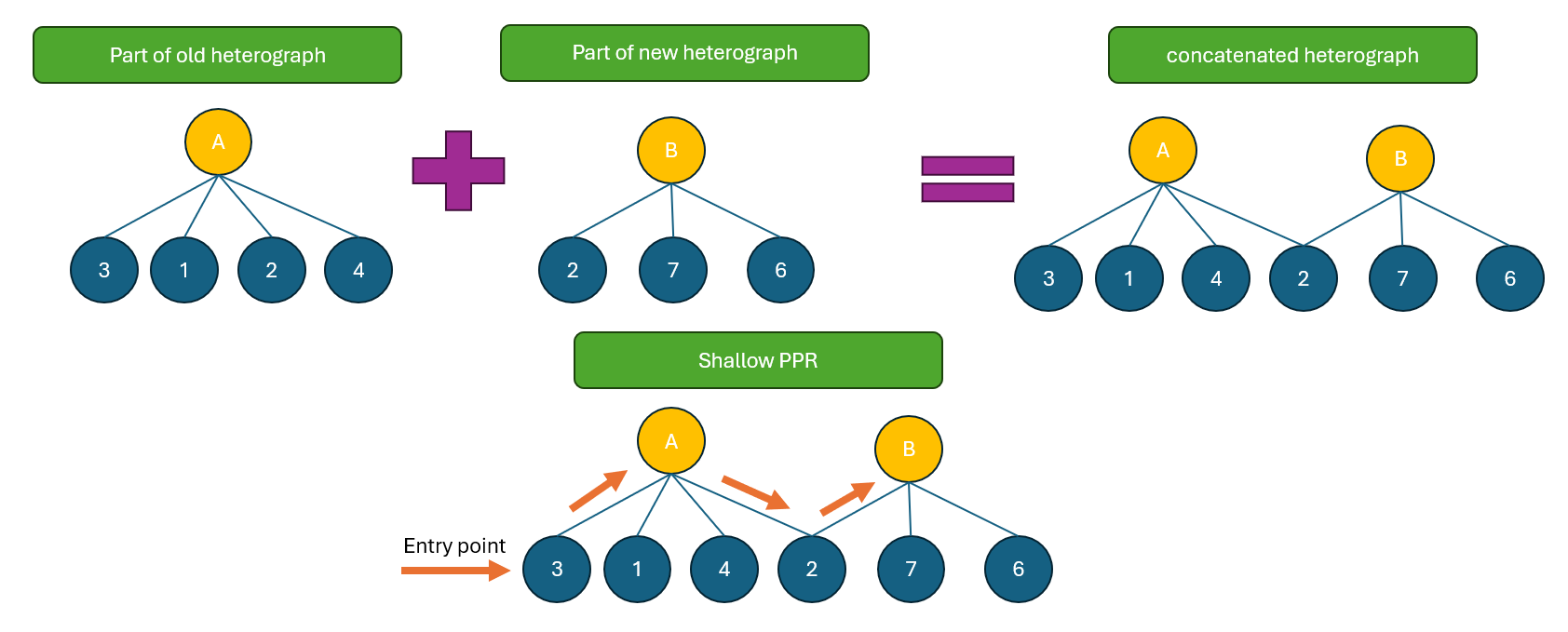
图3. NodeRAG无缝合并新旧图,实现高效且上下文感知的更新