🚀 NodeRAG 是一个基于异构图的生成和检索 RAG 系统,您可以通过多种方式安装和使用它。🖥️ 我们还提供了用户界面(本地部署)和便捷的可视化生成工具。📊 点击这里查看快速入门指南✨。您可以阅读我们的论文 📄了解更多信息。关于实验讨论,请查看我们的博客文章 📝。如果您想为我们的项目做出贡献,请访问我们的 GitHub 仓库 🤝。
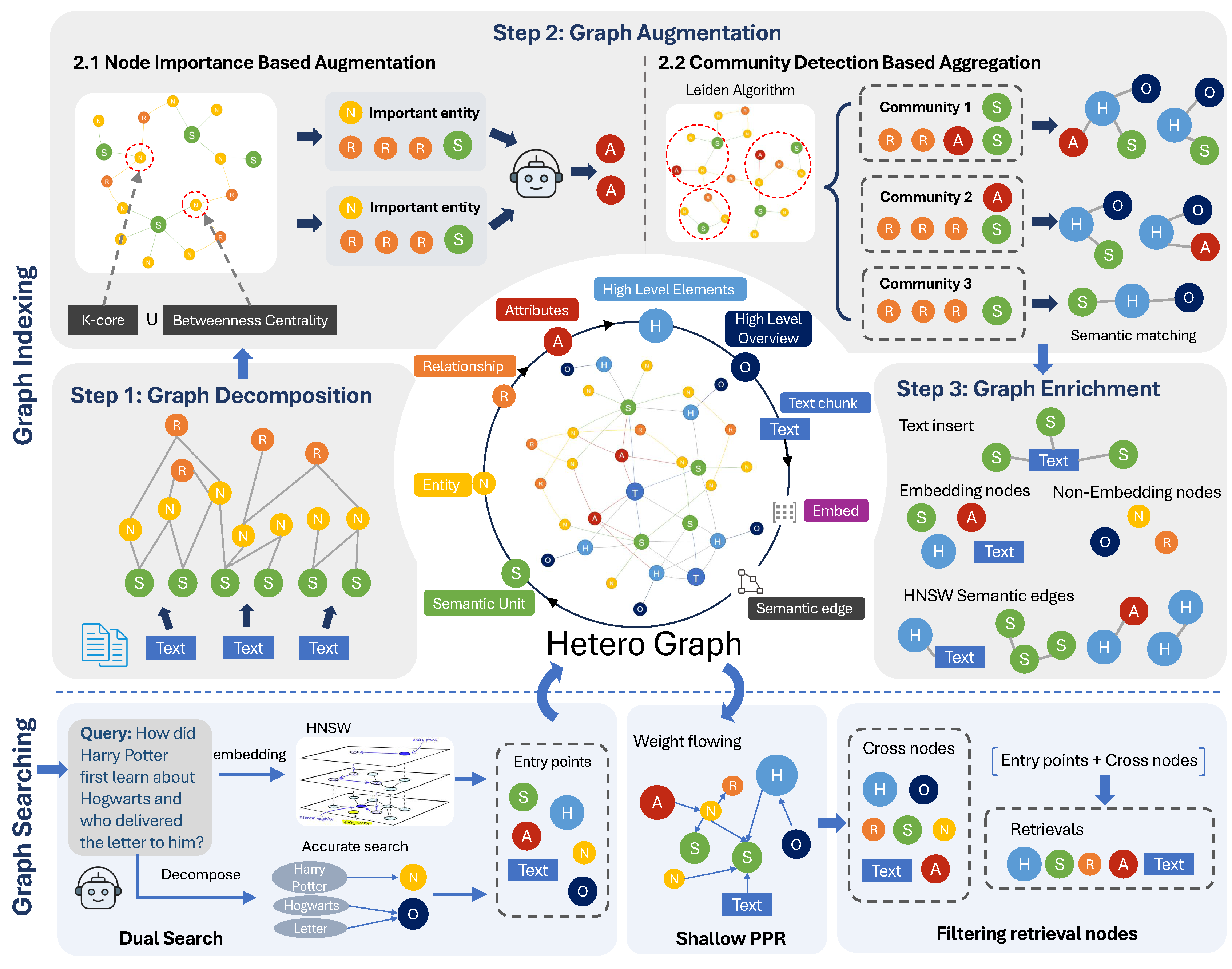
NodeRAG 系统架构
This is the multi-page printable view of this section. Click here to print.
为 NodeRAG 创建并激活虚拟环境:
conda create -n NodeRAG python=3.10
conda activate NodeRAG
uv(可选:更快的包安装)要加速包安装,可以使用 uv:
pip install uv
使用 uv 安装 NodeRAG 以获得优化的性能:
uv pip install NodeRAG
下一步,请查看构建文档以索引您的语料库。
在从源码安装 NodeRAG 之前,请确保您具备以下要求:
requirements.txt - 核心依赖项requirements.in - 开发依赖项git clone https://github.com/Terry-Xu-666/NodeRAG.git
cd NodeRAG
conda create -n NodeRAG python=3.10
conda activate NodeRAG
pip install uv
uv pip install requirements.txtpip install requirements.txt下一步,请参阅构建文档以索引您的语料库。
NodeRAG 项目具有以下结构。您需要通过创建项目文件夹并在其中放置 input 文件夹来手动构建此结构。在 input 文件夹中,放置您需要进行 RAG 处理的语料库。
main_folder/
├── input/
│ ├── file1.md
│ ├── file2.txt
│ ├── file3.docx
│ └── ...
.md、.doc 和 .txt。下载这个 txt 文件 作为快速示例到您的输入文件夹。
python -m NodeRAG.build -f path/to/main_foulder
当您第一次使用此命令时,它将在 main_folder 目录中创建 Node_config.yaml 文件。

根据以下说明修改配置文件(添加 API 和服务提供商),以确保 NodeRAG 可以访问正确的 API。
要快速使用 NodeRAG 演示,请设置您的 OpenAI 账户的 API 密钥。如果您没有 API 密钥,请参考 OpenAI Auth。确保在 model_config 和 embedding_config 部分都输入 API 密钥。
有关详细的配置和修改说明,请参见 配置指南。
#==============================================================================
# AI 模型配置
#==============================================================================
model_config:
model_name: gpt-4o-mini # 用于文本生成的模型名称
api_keys: # 您的 API 密钥(可选)
embedding_config:
api_keys: # 您的 API 密钥(可选)
配置设置完成后,重新运行以下命令:
python -m NodeRAG.build -f path/to/main_folder
终端将显示状态树:
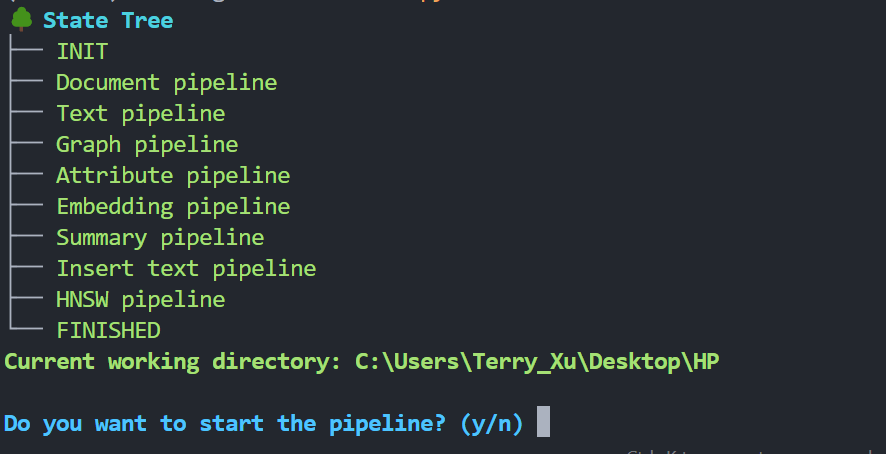
按 y 继续。等待工作流程完成。

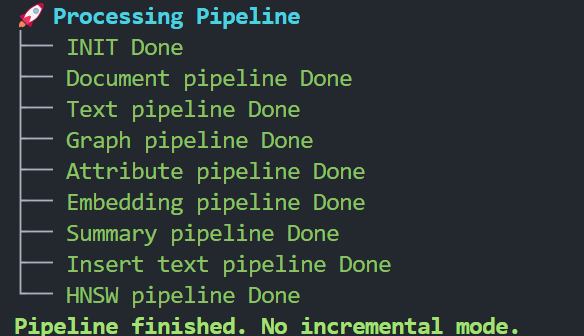
索引过程随后将完成。最终结构(生成后)将在 NodeRAG 文件结构文档 中进行解释。
下一步,请参见 Answer 文档 以生成特定领域的答案。
NodeRAG 支持增量更新。它通过跟踪已索引文档的哈希 ID 来高效管理更新。
请勿修改已经完成索引的文件,因为这可能导致重复索引或不可预测的错误。
要添加新文档,请将新文件放入 input 文件夹,然后重新运行索引命令:
python -m NodeRAG.build -f path/to/main_folder
NodeRAG 将自动检测新文件并将其转换为内部数据库格式,而无需重新处理现有数据。
关于增量模式以及 GraphRAG 和 LightRAG 在增量更新方面的比较,请参阅这篇博客文章。
使用 NodeRAG 有两种方式:
每种方法都有其优势。直接导入为本地使用提供了简单直接的集成方式。但是,如果你计划将 NodeRAG 部署为服务,使用 API 客户端被认为是最佳实践。
通过最简单的设置快速构建搜索引擎:
from NodeRAG import NodeConfig, NodeSearch
# 从主文件夹加载配置
config = NodeConfig.from_main_folder(r"C:\Users\Terry_Xu\Desktop\HP")
# 初始化搜索引擎
search = NodeSearch(config)
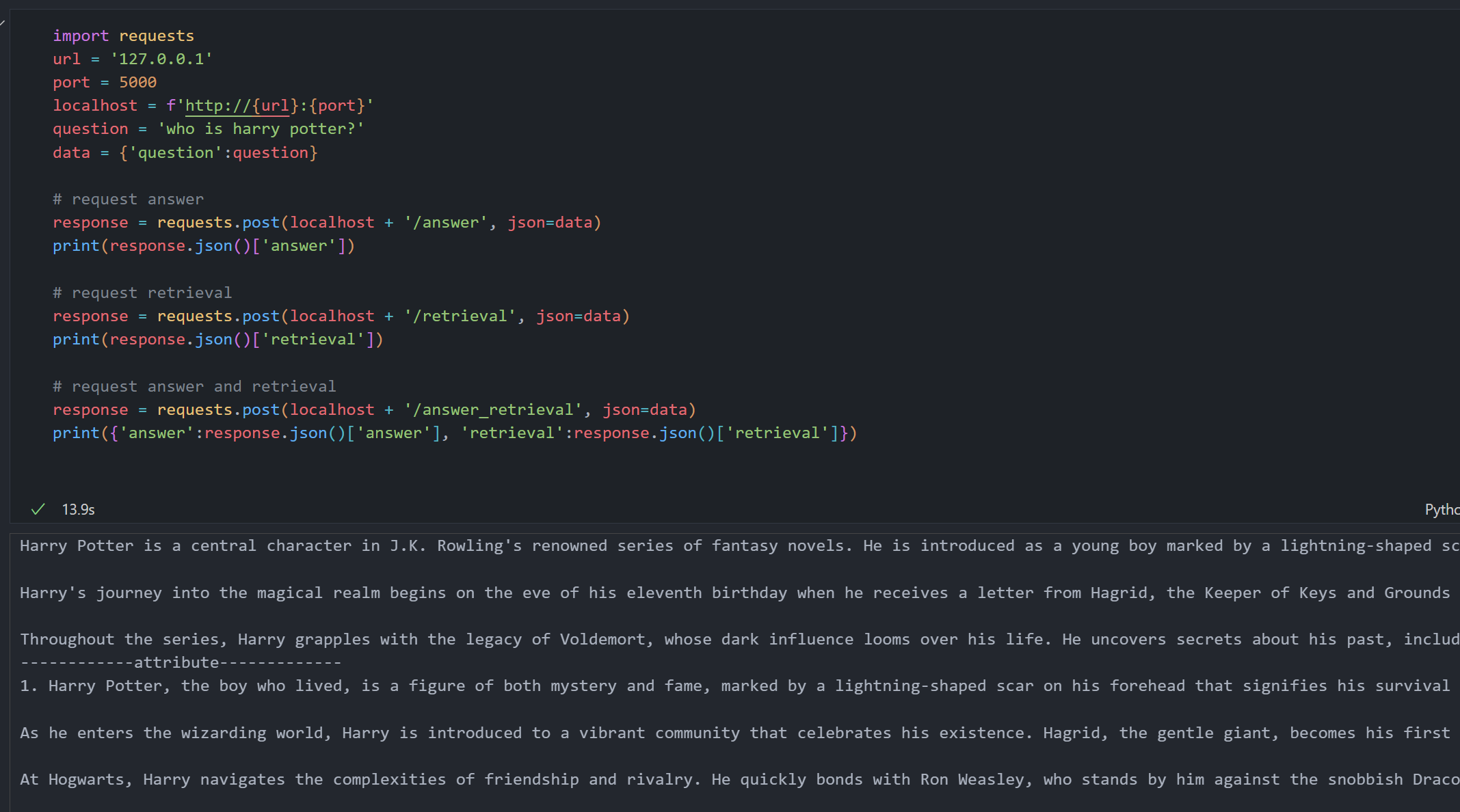
# 查询系统
ans = search.answer('who is harry potter?')
# 'ans' 是一个包含多个可访问属性的对象:
# response:对您问题的生成答案
print(ans.response)
# 答案中的 token 数量
print(ans.response_tokens)
# 检索信息:用于生成答案的上下文
print(ans.retrieval_info)
# 检索上下文中的 token 数量
print(ans.retrieval_tokens)
search.answer() 返回一个对象,该对象同时包含答案和检索上下文,以及有用的元数据。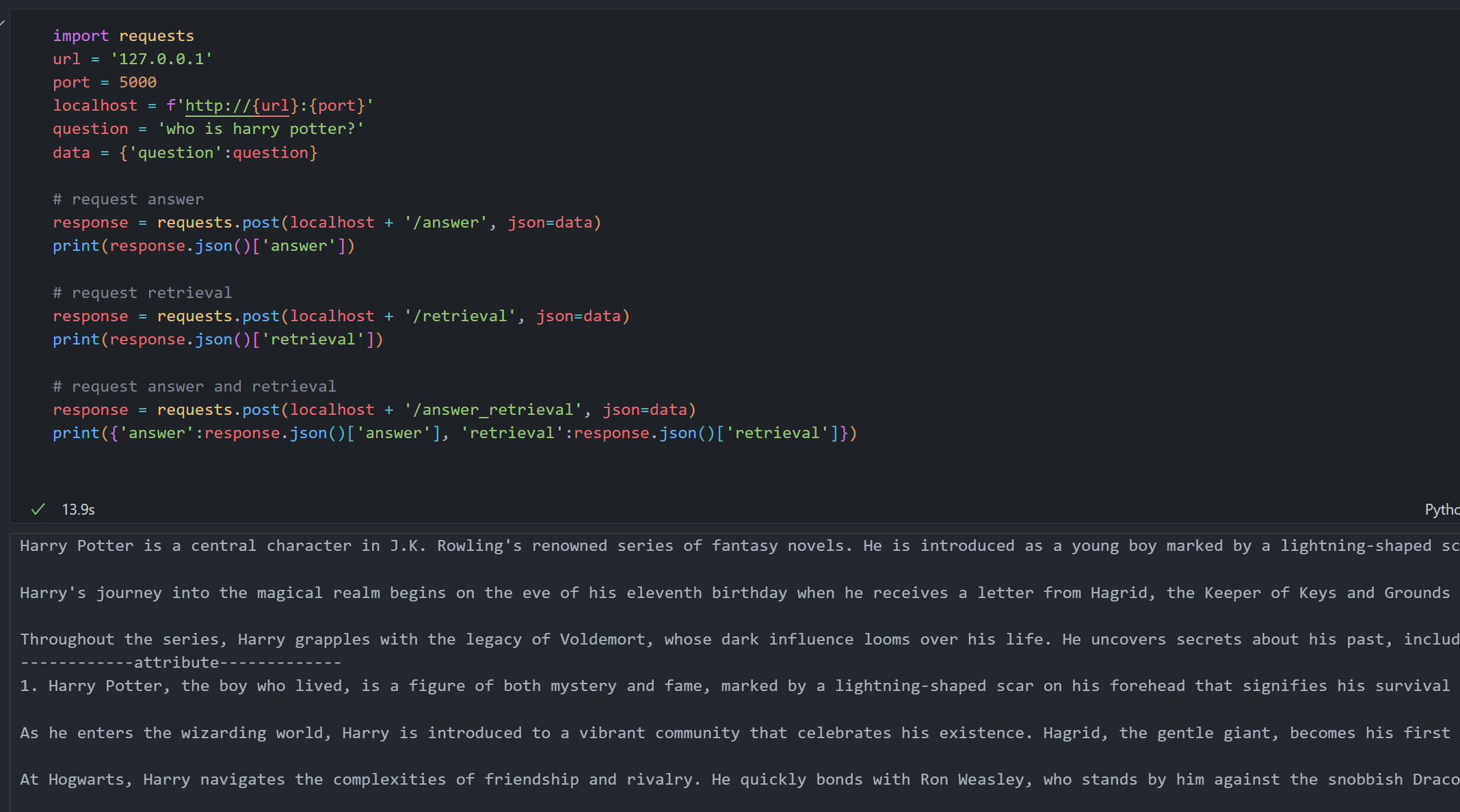
确保您已经完成语料库的索引,然后使用以下命令启动 API 服务器:
python -m NodeRAG.search -f path/to/main_folder
这将启动一个基于 Flask 的 API 客户端。

您可以通过更新配置文件中的 config.url 和 config.port 来修改 localhost 地址和端口。
#==============================================================================
# 文档处理配置
#==============================================================================
config:
# 搜索服务器设置
url: '127.0.0.1' # 搜索服务的服务器 URL
port: 5000 # 服务器端口号
设置完客户端后,您可以直接从命令行使用 NodeRAG。请求代码已完全封装,便于使用。
python -m NodeRAG -f path/to/main_folder -q "您的问题"
要检索相关上下文,使用 -r 标志:
python -m NodeRAG -f path/to/main_folder -q "您的问题" -r
要同时检索答案和相关上下文,使用 -r -a 标志:
python -m NodeRAG -f path/to/main_folder -q "您的问题" -r -a
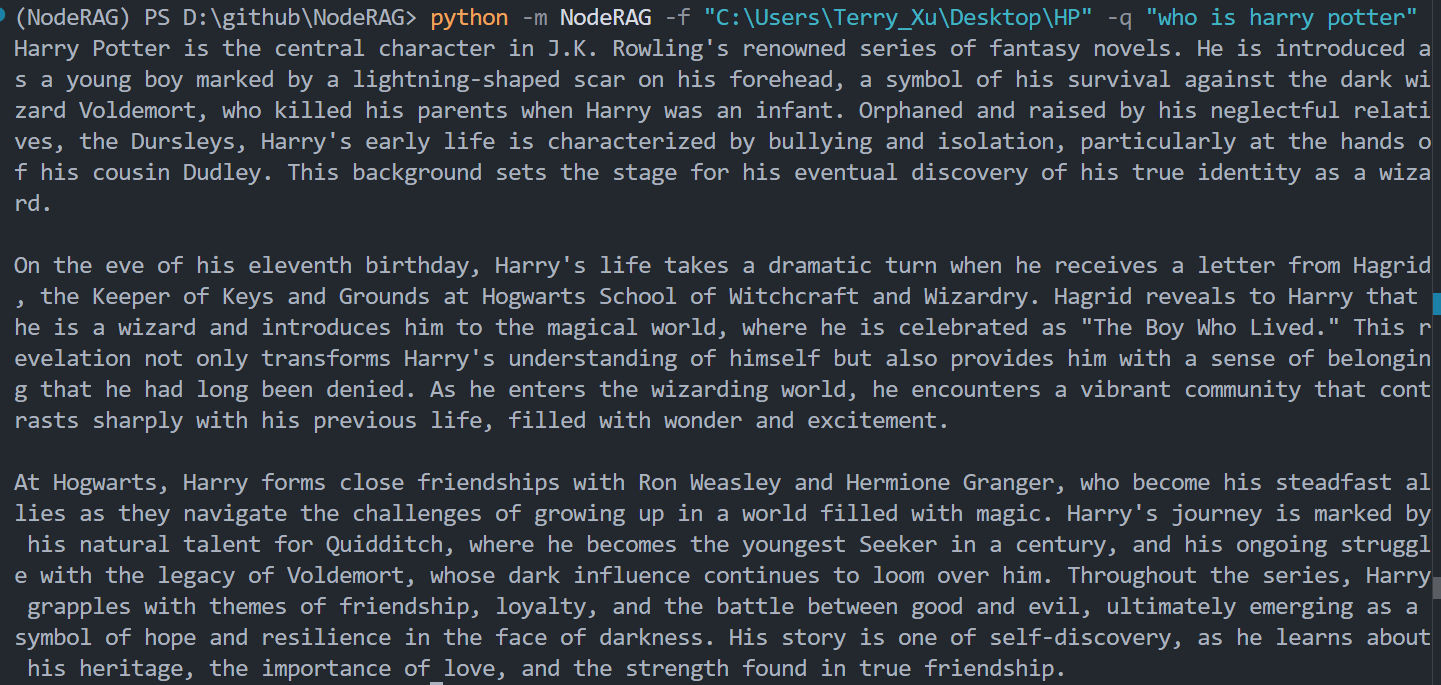
您可以通过 HTTP 请求在 Python 或 Jupyter Notebook 中与 NodeRAG API 交互。以下是一个常见的使用示例。
import requests
# 配置 API 端点
url = '127.0.0.1'
port = 5000
localhost = f'http://{url}:{port}'
question = 'who is harry potter?'
data = {'question': question}
# 仅请求答案
response = requests.post(localhost + '/answer', json=data)
print(response.json()['answer'])
# 仅请求检索上下文
response = requests.post(localhost + '/retrieval', json=data)
print(response.json()['retrieval'])
# 同时请求答案和检索上下文
response = requests.post(localhost + '/answer_retrieval', json=data)
result = response.json()
print({'answer': result['answer'], 'retrieval': result['retrieval']})
POST /answer:返回对您查询的生成答案。POST /retrieval:返回从语料库中检索的相关上下文。POST /answer_retrieval:返回答案及其相关上下文。⚙️ 注意: 发送请求前请确保 API 服务器正在运行。您可以通过
Node_config.yaml中的config.url和config.port配置主机和端口。
python -m NodeRAG.build -f path/to/main_foulder
当您首次使用此命令时,它将在main_folder目录中创建Node_config.yaml文件。

您需要按照以下说明修改配置文件(添加 API 和服务提供商)以确保 NodeRAG 可以访问正确的 API。
#==============================================================================
# AI 模型配置
#==============================================================================
model_config:
service_provider: openai # AI 服务提供商(如 openai、azure)
model_name: gpt-4o-mini # 文本生成模型名称
api_keys: # 您的 API 密钥(可选)
temperature: 0 # 文本生成的温度参数
max_tokens: 10000 # 生成的最大令牌数
rate_limit: 40 # API 速率限制(每秒请求数)
embedding_config:
service_provider: openai_embedding # 嵌入服务提供商
embedding_model_name: text-embedding-3-small # 文本嵌入模型名称
api_keys: # 您的 API 密钥(可选)
rate_limit: 20 # 嵌入请求的速率限制
#==============================================================================
# 文档处理配置
#==============================================================================
config:
# 基本设置
main_folder: C:\Users\Terry_Xu\Desktop\HP # 文档处理的根文件夹
language: English # 文档处理语言
docu_type: mixed # 文档类型(mixed、pdf、txt 等)
# 分块设置
chunk_size: 1048 # 处理的文本块大小
embedding_batch_size: 50 # 嵌入处理的批量大小
# UI 设置
use_tqdm: false # 启用/禁用进度条
use_rich: true # 启用/禁用富文本格式
# HNSW 索引设置
space: l2 # HNSW 的距离度量(l2、cosine)
dim: 1536 # 嵌入维度(必须与嵌入模型匹配)
m: 50 # HNSW 每层的连接数
ef: 200 # HNSW 中动态候选列表的大小
m0: # HNSW 中双向链接的数量
# 摘要设置
Hcluster_size: 39 # 高级元素匹配的集群数
# 搜索服务器设置
url: '127.0.0.1' # 搜索服务的服务器 URL
port: 5000 # 服务器端口号
unbalance_adjust: true # 启用不平衡数据调整
cross_node: 10 # 返回的交叉节点数
Enode: 10 # 返回的实体节点数
Rnode: 30 # 返回的关系节点数
Hnode: 10 # 返回的高级节点数
HNSW_results: 10 # HNSW 搜索结果数
similarity_weight: 1 # 个性化 PageRank 中的相似度权重
accuracy_weight: 1 # 个性化 PageRank 中的准确度权重
ppr_alpha: 0.5 # 个性化 PageRank 的阻尼因子
ppr_max_iter: 2 # 个性化 PageRank 的最大迭代次数
我们目前支持的模型服务提供商包括 openai 和 genmini。对于嵌入模型,我们支持 openai_embedding 和 gemini embedding。我们强烈推荐使用 openai 作为模型提供商。这是因为 OpenAI 的结构解码功能可以有效地遵循结构化分解提示来生成异构图,提供了很好的稳定性。遗憾的是,目前的 Gemini 模型和其他模型(如 DeepSeek),即使是最新的 Gemini 2.0,在结构化输出方面都表现出不稳定性。我们在这篇博客中讨论了这个问题。
当您选择服务提供商时,您可以使用他们当前提供的所有可用模型。
例如,如果您选择 openai 作为服务提供商,您可以使用他们网站上最新模型列表中的所有模型。
以下是 openai 的一些可用模型示例:
对于嵌入模型,openai_embedding 提供:
请参考嵌入获取最新的可用模型列表。
OpenAI 账户受到速率限制,包括每分钟请求数和令牌数的限制。您可以通过设置适当的速率限制来调整嵌入模型和语言模型的请求速率,以控制使用峰值。
有关账户等级和具体速率限制的更多信息,请参见 OpenAI 速率限制指南。
目前支持英语和中文。要添加对其他语言的支持,请修改提示相关文本并相应更新 prompt manager 中的语言返回字段。详情请参见提示微调。
dim 表示嵌入向量的维度数。请确保此值与您使用的嵌入模型相匹配。例如,OpenAI 的嵌入维度是 1536,而 Gemini 的嵌入维度是 768。
您可以在这里找到所有提示模板。
自定义提示的最简单方法是打开文件并根据需要直接修改英文和中文提示文本。
您可以通过定义相应的提示并在提示管理器中注册它们来添加对其他语言的支持。
要添加新语言(例如,德语),在相关提示文件中为该语言定义提示。
例如,在decompose.py中,添加:
decompos_query = '''
Please break down the following query into a single list...
Query:{query}
'''
decompos_query_Chinese = '''
请将以下问题分解为一个 list...
问题:{query}
'''
decompos_query_German = '''
Bitte zerlegen Sie die folgende Anfrage in eine einzelne Liste...
Anfrage:{query}
'''
接下来,在提示管理器中注册您的新提示:
打开prompt_manager.py并执行以下操作:
match语句中添加一个新的case来处理该语言第67行示例:
@property
def answer(self):
match self.language:
case 'English':
return answer_prompt
case 'Chinese':
return answer_prompt_Chinese
case 'German':
return answer_prompt_German
case _:
return self.translate(answer_prompt)
以下结构是索引过程完成后生成的。每个文件夹和文件都有特定用途,用于高效检索和基于图的推理。
main_foulder/
├── cache/
│ ├── attributes.parquet
│ ├── documents.parquet
│ ├── entities.parquet
│ ├── graph.pkl
│ ├── high_level_elements.parquet
│ ├── high_level_elements_titles.parquet
│ ├── hnsw_graph.pkl
│ ├── HNSW.bin
│ ├── id_map.parquet
│ ├── relationship.parquet
│ ├── semantic_units.parquet
│ ├── text_decomposition.jsonl
│ └── text.parquet
│
├── info/
│ ├── document_hash.json
│ ├── indices.json
│ ├── info.log
│ └── state.json
│
├── input/
│ └── J. K. Rowling - Harry Potter 1 - Sorcerer's Stone.txt
│
└── Node_config.yaml
cache/存储所有处理过的数据,包括语义结构、嵌入向量和图数据,优化用于快速检索和推理。
attributes.parquet:存储从语料库中提取的元数据属性。documents.parquet:包含处理后的文档级数据条目。entities.parquet:提取的命名实体,用于链接和图构建。graph.pkl:基于哈希 ID 的序列化异构图。high_level_elements.parquet:聚合的高级单元(例如,高级概念)。high_level_elements_titles.parquet:高级元素的标题,用于结构化导航。hnsw_graph.pkl / HNSW.bin:HNSW(层次可导航小世界)索引,用于快速相似性搜索。id_map.parquet:将内部 ID 映射到节点。relationship.parquet:实体或语义单元之间的关系数据。semantic_units.parquet:用于细粒度查询的核心语义内容单元。text_decomposition.jsonl:以 JSON Lines 格式存储的分解文本数据,用于索引。text.parquet:以高效方式存储的原始或轻度处理的文本段。info/包含索引状态、日志和元数据,用于跟踪和可重现性。
document_hash.json:输入文档的哈希值,用于变更检测和增量更新。indices.json:关于各节点数量的信息。info.log:捕获处理步骤和时间的日志文件。state.json:工作流状态快照,用于恢复或审计索引过程。input/索引过程的输入文件和配置。
*.(txt, md):示例输入语料库。配置Node_config.yaml:配置文件,指定索引参数、模型设置和路径。NodeRAG项目具有以下结构。您需要通过创建项目文件夹并在其中放置input文件夹来手动构建此结构。在input文件夹中,放置您需要用于RAG的语料库。
main_folder/
├── input/
│ ├── file1.md
│ ├── file2.txt
│ ├── file3.docx
│ └── ...
.md、.doc和.txt。下载这个txt文件作为快速示例到您的input文件夹。
要启动WebUI,运行以下命令:
python -m NodeRAG.WebUI -f "C:\Users\Terry_Xu\Desktop\HP"
注意: 首次运行此命令时看到错误是正常的。
NodeRAG将自动在您的主文件夹中创建一个Node_config.yaml文件。
修改配置文件以包含您的API凭证和服务提供商详细信息。
这确保NodeRAG可以访问正确的API端点。
要快速试用NodeRAG演示,添加您的OpenAI API密钥。
如果您没有API密钥,请参考OpenAI Auth。
在model_config和embedding_config部分都输入API密钥。
Node_config.yaml)#==============================================================================
# AI模型配置
#==============================================================================
model_config:
model_name: gpt-4o-mini # 用于文本生成的模型
api_keys: # 在此处输入您的OpenAI API密钥
embedding_config:
api_keys: # 在此处输入您的OpenAI API密钥
有关详细的配置说明,请参阅配置指南。
完成配置后,返回浏览器并刷新页面。
您现在应该能正确看到WebUI界面。
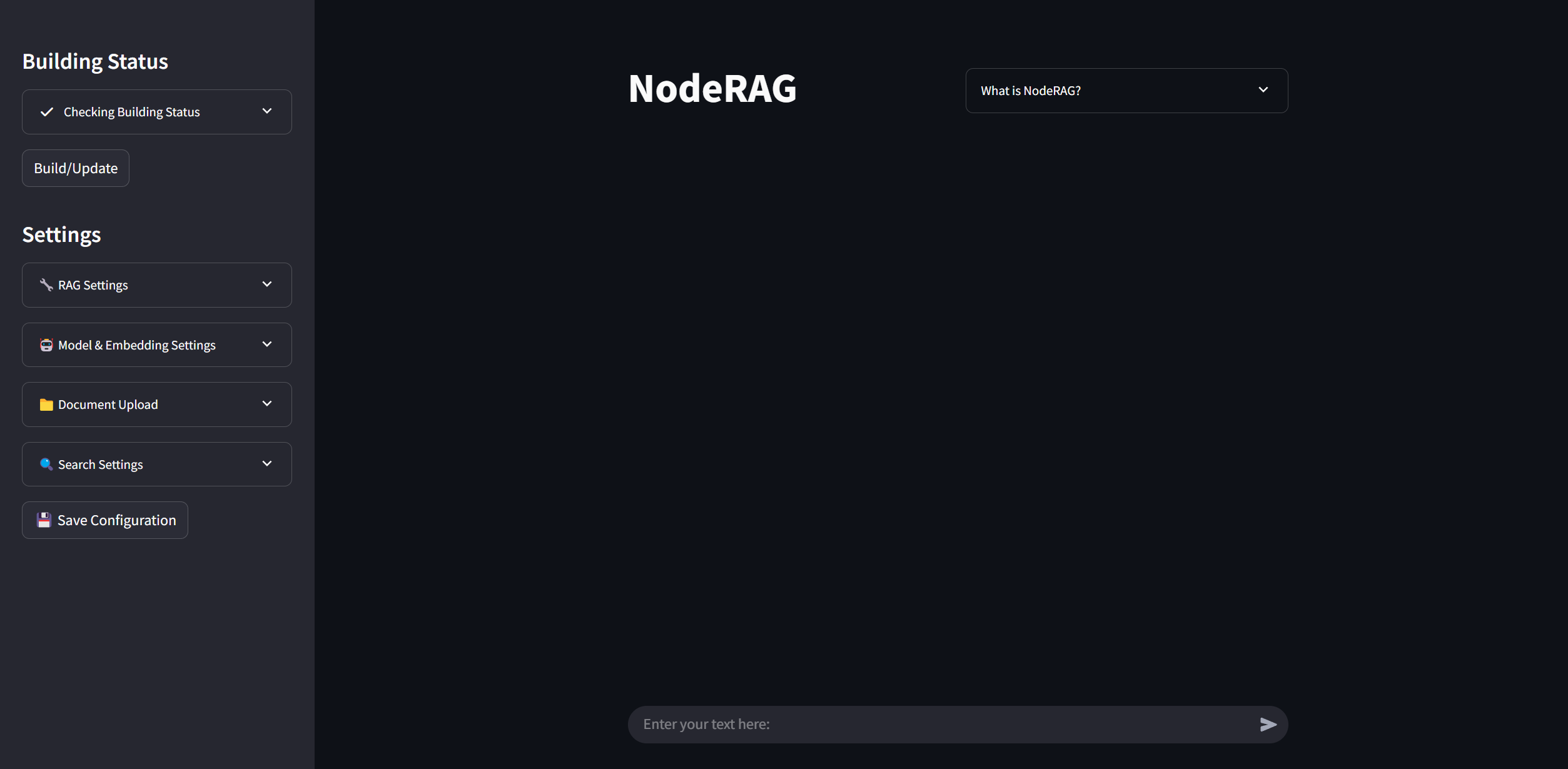
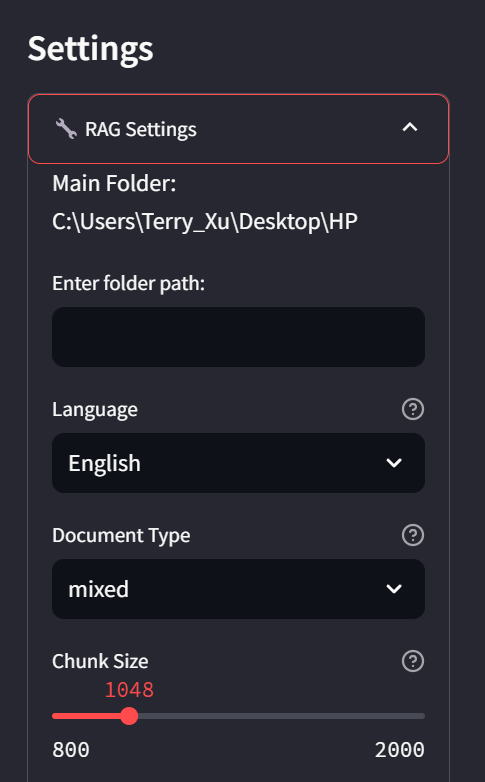
在侧边栏中,您可以查看当前状态和配置参数。
您可以调整这些参数以满足您的偏好。
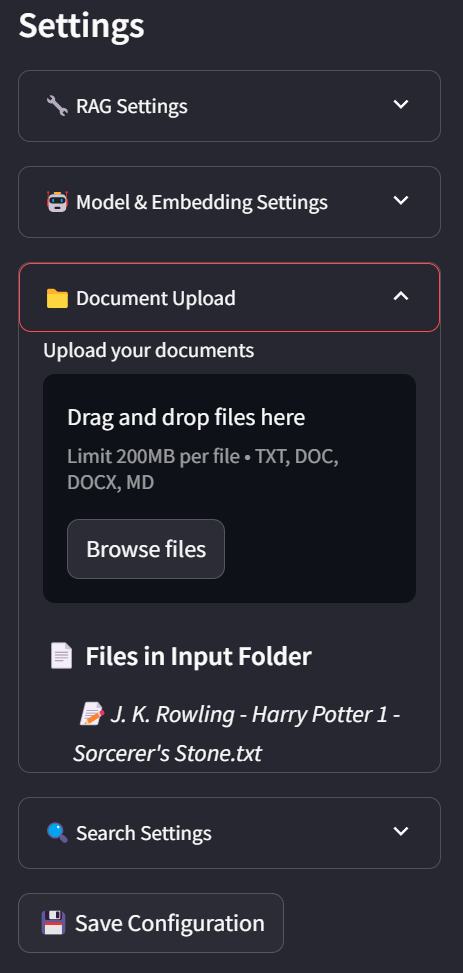
您还可以通过直接将文件拖到文件系统面板中来导入文件。
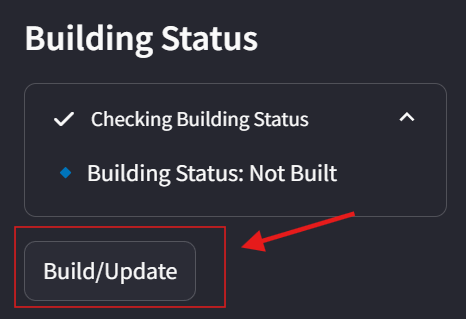
要保存所有配置设置,请点击Save Config按钮。
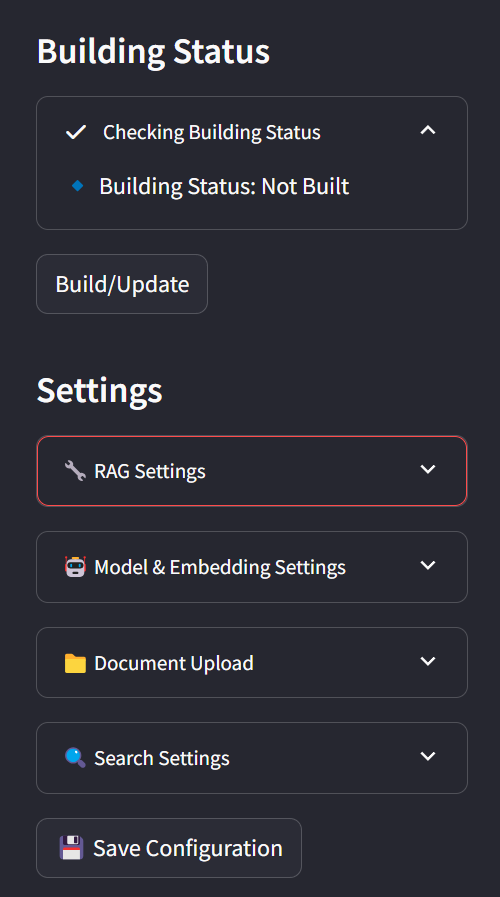
准备就绪后,点击Build按钮开始为您的语料库建立索引。
构建索引可能需要一些时间,具体取决于您的语料库大小。
您可以通过WebUI或Python后端的日志监控进度。
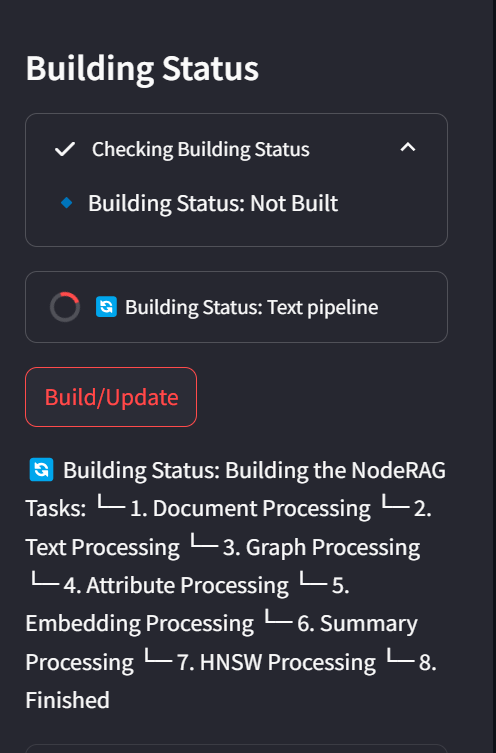
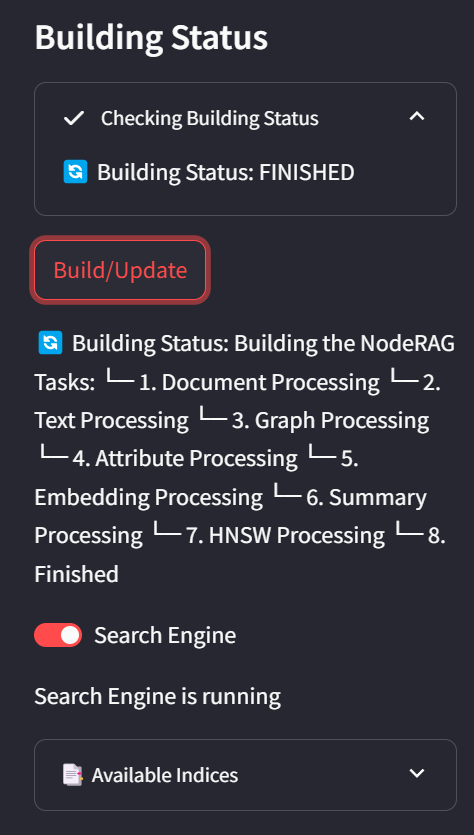
构建完成后,您将看到Search Engine选项已启用,状态将显示Finished,并且Indices部分将出现。
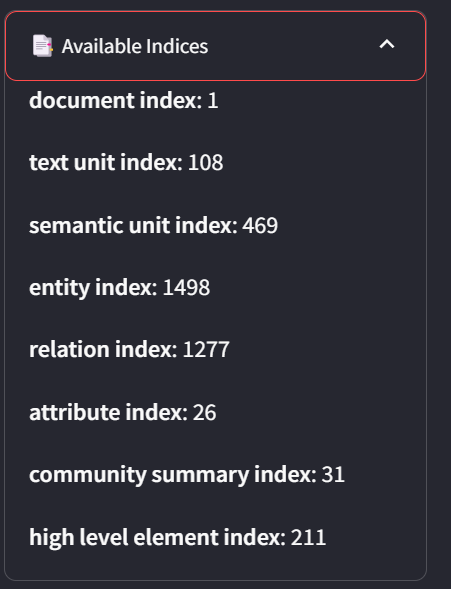
在Indices标签中,您可以查看语料库中所有节点的详细统计信息。
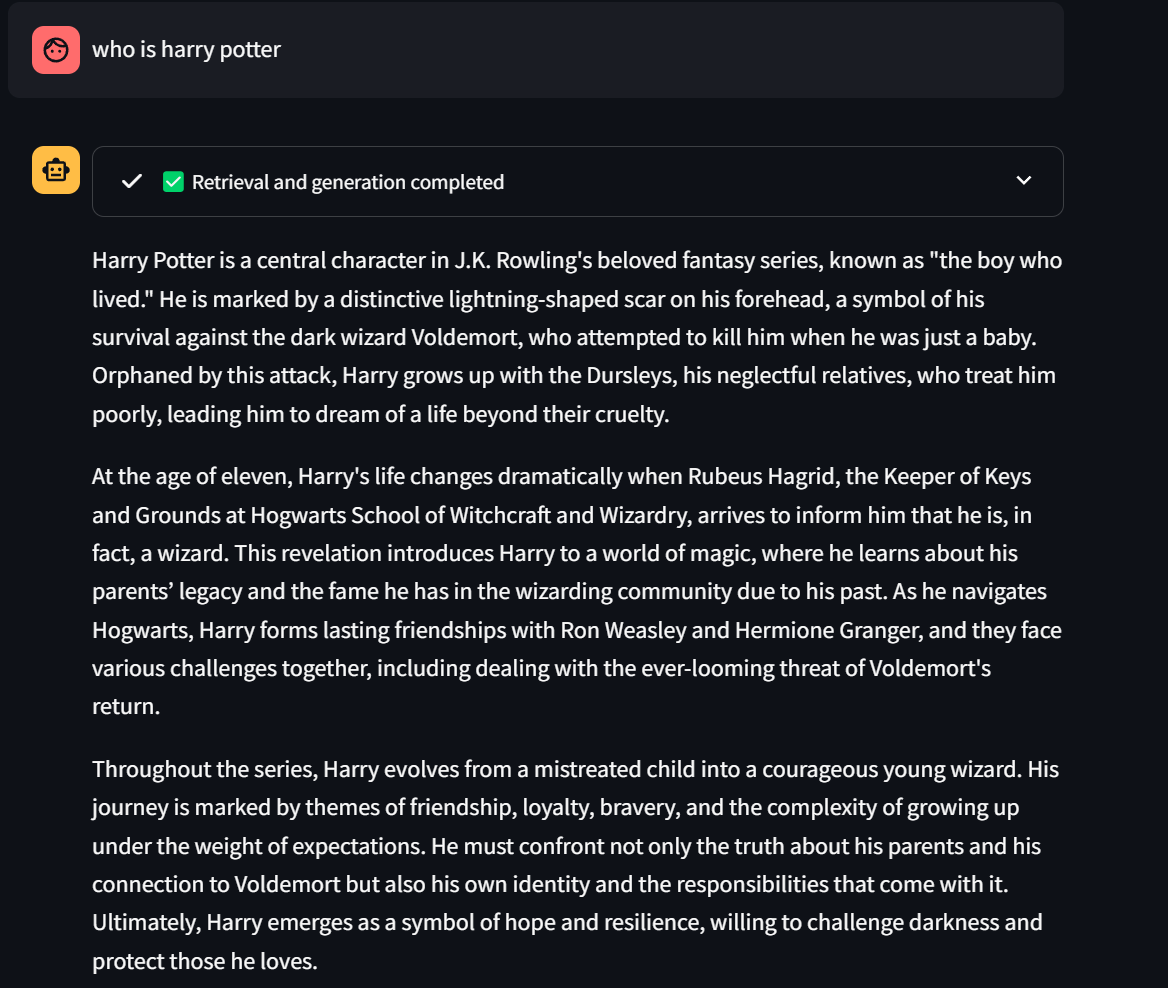
🎯 是时候提出领域特定的问题了 — 欢呼吧!🎉
📄 相关的检索上下文将显示在每个答案的上方。
生成可视化最简单的方法是运行单个命令。 这将根据您的索引数据创建一个交互式HTML页面。
您可以在这里查看基于哈利波特语料库的实时示例:示例
python -m NodeRAG.Vis.html -f path/to/main_folder
您还可以使用-n标志控制显示的节点数量。
注意: 最终显示的节点数可能会超过您选择的值,因为我们应用内部优化以提高可视化质量。 我们稍后将解释可视化过程背后的细节。
python -m NodeRAG.Vis.html -f path/to/main_folder -n 600

生成具有数千甚至数万个节点和边的可视化非常消耗资源,通常对浏览器来说是不切实际的。 因此,NodeRAG的可视化不会使用语料库中的所有节点。相反,它会根据相关性有选择地包含固定数量的重要节点。
节点重要性使用PageRank算法计算。
NodeRAG按重要性对所有节点进行排名,并选择排名前n的节点进行可视化,其中n由用户定义。
最佳实践: 将
n设置为1000或更少以获得最佳性能。更高的值可能会导致HTML浏览器中出现渲染问题。
一个常见问题是排名靠前的节点可能不会形成完全连通的图。 为了解决这个问题,NodeRAG在其异构图上应用双向Dijkstra算法来提取额外的连接节点。 这确保了最终的可视化是完全连通的,没有孤立的节点。
注意: 这就是为什么您的可视化中的节点总数可能会超过您指定的
n值。