🔬 我们提供了一个完整的复现仓库,其中包含了我们对 NaiveRAG、HYDE 和 NodeRAG 的实现,以及我们在实验中使用的 LightRAG 和 GraphRAG 的快照版本和参数设置。
📊 实验中使用的基准测试数据集大多已经过处理。您可以在基准测试部分找到处理细节和我们的理由,以及如何快速获取可用数据的指导。
🔗 我们的复现仓库位于 NodeRAG_reproduce。
This is the multi-page printable view of this section. Click here to print.
🔬 我们提供了一个完整的复现仓库,其中包含了我们对 NaiveRAG、HYDE 和 NodeRAG 的实现,以及我们在实验中使用的 LightRAG 和 GraphRAG 的快照版本和参数设置。
📊 实验中使用的基准测试数据集大多已经过处理。您可以在基准测试部分找到处理细节和我们的理由,以及如何快速获取可用数据的指导。
🔗 我们的复现仓库位于 NodeRAG_reproduce。
我们观察到,许多当前的基准测试不再符合现代RAG设置。传统的RAG基准测试处理段落,在LLM生成答案之前从有限的集合中选择相关段落。当前的RAG设置更接近现实场景,我们直接处理原始语料库进行检索和回答。因此,我们修改了现有的多跳数据集,将所有段落合并到单个语料库中并评估最终答案。认识到RAG主要关注检索系统质量,我们在评估中保持了一致的问答设置以确保公平比较。
您应该将所有语料库合并到一个语料库中,然后使用每个RAG系统的索引功能将其索引到各自的数据库中。
将您的问题和答案以键值对的形式保存在parquet文件格式中。然后您可以直接使用我们提供的"LLM作为评判"脚本进行测试。
我们提供了我们使用的大部分数据集,这些数据集已经被处理成易于使用的格式。但是,由于某些数据集的版权要求,请联系任何作者以获取我们处理过的数据集和评估parquet文件。
您可以通过发送邮件给任何一位作者来获取数据集。
您将在 Google Drive 中找到一个 RAG Arena 文件夹。请将该文件夹中的数据文件放入您 GitHub 仓库中的 rag-qa-arena 文件夹中。
在原始命令中添加 -a 标志可以跳过评估并获取原始 parquet 文件。
例如:
python -m /eval/eval_node -f path/to/main_folder -q path/to/question_parquet -a
使用 rag-qa-arena 文件夹中的 change.ipynb 将 parquet 转换为评估用的 JSON 格式。将处理后的 JSON 文件放在 data/pairwise_eval 文件夹中,按照以下结构组织:
📁 rag-qa-arena
└── 📁 data
└── 📁 pairwise_eval
└── 📁 GraphRAG
├── 📄 fiqa.json
├── 📄 lifestyle.json
├── 📄 recreation.json
├── 📄 science.json
├── 📄 technology.json
└── 📄 writing.json
└── 📁 NodeRAG
├── 📄 fiqa.json
├── 📄 lifestyle.json
├── 📄 recreation.json
├── 📄 science.json
├── 📄 technology.json
└── 📄 writing.json
└── 📁 NaiveRAG
├── 📄 fiqa.json
├── 📄 lifestyle.json
├── 📄 recreation.json
├── 📄 science.json
├── 📄 technology.json
└── 📄 writing.json
修改脚本,添加您的 openai_key。
对于 Mac 和 Linux 系统:
bash run_pairwise_eval_lfrqa.sh
对于 Windows 系统:
run_pairwise_eval_lfrqa.bat
修改脚本,添加您的 openai_key。
对于 Mac 和 Linux 系统:
bash run_pairwise_eval_llms.sh
对于 Windows 系统:
run_pairwise_eval_llm.bat
您应该修改 model1 和 model2 以确保每个模型都与其他模型进行比较。例如,您可以将 NaiveRAG 与其他四个模型进行比较,然后将 Hyde 与剩余的三个模型(不包括 NaiveRAG)进行比较,以此类推,直到完成所有成对比较。
python code/report_results.py --use_complete_pairs
此脚本会报告所有比较的胜率和胜率+平局率,并输出一个 all_battles.json 文件。
NaiveRAG 可以使用 NodeRAG 环境。如果您已经安装了 NodeRAG conda 环境,可以直接使用 NaiveRAG 进行索引。如果您还没有安装 NodeRAG 环境,请参考文档中的快速入门指南。
您需要一个类似于 NodeRAG 的文件夹结构。创建一个名为 main_folder 的主工作目录,并在其中放置一个 input 文件夹。将您想要索引的文件放在 input 文件夹中。
main_folder/
├── input/
│ ├── file1.md
│ ├── file2.txt
│ ├── file3.docx
│ └── ...
然后运行
python -m NaiveRAG.build -f path/to/main_folder
首先,根据基准测试格式准备您的测试问题。您需要创建一个包含问题及其对应答案的测试集 parquet 文件。准备好后,您可以使用以下命令运行评估:
python -m /eval/eval_naive -f path/to/main_folder -q path/to/question_parquet
HYDE 可以使用与 NaiveRAG 相同的索引基础。因此,在完成 NaiveRAG 索引过程后,您可以直接使用其索引基础。
首先,按照基准测试格式准备您的测试问题。您需要创建一个包含问题及其对应答案键的测试集 parquet 文件。准备好后,您可以使用以下命令运行评估:
python -m /eval/eval_hyde -f path/to/naive_main_folder -q path/to/question_parquet
为确保实验的一致性和命令的可用性,请按照以下说明安装 GraphRAG:
conda create -n graphrag python=3.9
conda activate graphrag
pip install graphrag==1.2.0
graphrag init --root path/to/main_folder
这将在 main_folder 目录中创建两个文件:
.env:包含 GraphRAG 流程的环境变量
GRAPHRAG_API_KEY=<API_KEY> 用于 OpenAI/Azure OpenAI 认证settings.yaml:包含可配置的流程设置
有关 GraphRAG 配置和使用的更多详细信息,请参阅官方文档。
然后通过运行以下命令进行索引:
graphrag index --root path/to/main_folder
首先,根据基准测试格式准备您的测试问题。您需要创建一个包含问题及其对应答案的测试集 parquet 文件。准备好后,您可以使用以下命令运行评估:
python -m /eval/eval_graph -f path/to/main_folder -q path/to/question_parquet
LightRAG 是我们实验的一个快照,其参数、函数和提示都经过微调,以返回统计数据并使用统一的提示。要开始使用,您首先需要创建一个新环境并安装 LightRAG 依赖项。
conad create -n lightrag python=3.10
conda activate lightrag
cd LightRAG
pip install -e .
与其他 RAG 实现类似,您需要创建一个名为 main_folder 的主工作目录,并在其中放置一个 input 文件夹来存储您的语料库文件。
main_folder/
├── input/
│ ├── file1.md
│ ├── file2.txt
│ ├── file3.docx
│ └── ...
然后运行
python -m Light_index -f path/to/main_folder
首先,根据基准测试格式准备您的测试问题。您需要创建一个包含问题及其对应答案键的测试集 parquet 文件。准备好后,您可以使用以下命令运行评估:
python -m /eval/eval_light -f path/to/main_folder -q path/to/question_parquet
python -m NodeRAG.build -f path/to/main_foulder
当您首次使用此命令时,它将在main_folder目录中创建Node_config.yaml文件。

根据以下说明修改配置文件(添加 API 和服务提供商),以确保 NodeRAG 可以访问正确的 API。
要快速使用 NodeRAG 演示,请设置您的 OpenAI 账户的 API 密钥。如果您没有 API 密钥,请参考 OpenAI 认证。确保您在model_config和embedding_config部分都输入了 API 密钥。
有关详细配置和修改说明,请参阅配置指南。
#==============================================================================
# AI 模型配置
#==============================================================================
model_config:
model_name: gpt-4o-mini # 用于文本生成的模型名称
api_keys: # 您的 API 密钥(可选)
embedding_config:
api_keys: # 您的 API 密钥(可选)
设置配置后,重新运行以下命令:
python -m NodeRAG.build -f path/to/main_folder
终端将显示状态树:
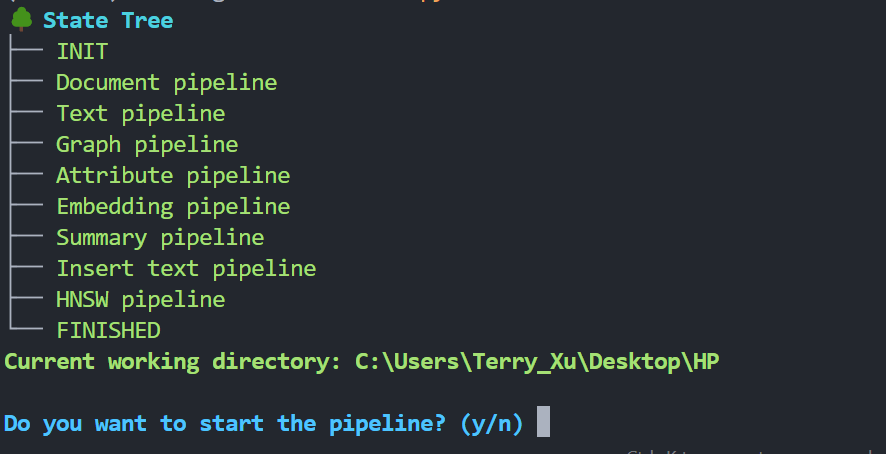
按y继续。等待工作流程完成。

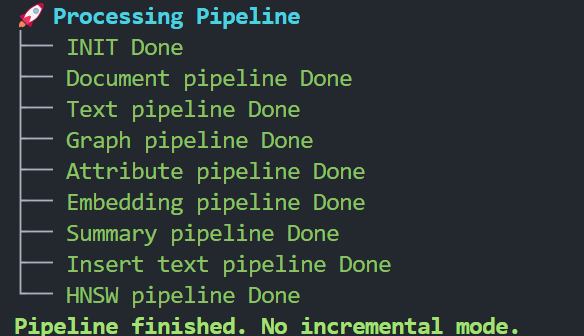
有关 NodeRAG 配置、索引和使用的更多详细信息,请参阅我们的文档。
首先,根据基准测试格式准备您的测试问题。您需要创建一个包含问题及其对应答案键的测试集 parquet 文件。准备好后,您可以使用以下命令运行评估:
python -m /eval/eval_node -f path/to/main_folder -q path/to/question_parquet