Thinking Before Looking: Improving Multimodal LLM Reasoning via Mitigating Visual Hallucination
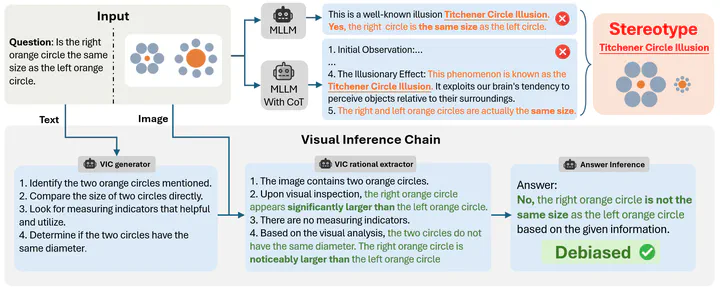 This example from HallusionBench demonstrates the differences between zero-shot, zero-shot CoT, and VIC. The zero-shot CoT represents the \textit{thinking while looking} approach, which tends to exhibit stereotypical reasoning patterns when processing both visual and textual inputs simultaneously. In contrast, our thinking before looking paradigm, VIC, enhances reasoning quality by decoupling the visual and textual inputs.
This example from HallusionBench demonstrates the differences between zero-shot, zero-shot CoT, and VIC. The zero-shot CoT represents the \textit{thinking while looking} approach, which tends to exhibit stereotypical reasoning patterns when processing both visual and textual inputs simultaneously. In contrast, our thinking before looking paradigm, VIC, enhances reasoning quality by decoupling the visual and textual inputs.Abstract
Multimodal large language models (MLLMs) have advanced the integration of visual and linguistic modalities, establishing themselves as the dominant paradigm for visual-language tasks. Current approaches like chain of thought (CoT) reasoning have augmented the cognitive capabilities of large language models (LLMs), yet their adaptation to MLLMs is hindered by heightened risks of hallucination in cross-modality comprehension. In this paper, we find that the thinking while looking paradigm in current multimodal CoT approaches–where reasoning chains are generated alongside visual input–fails to mitigate hallucinations caused by misleading images. To address these limitations, we propose the Visual Inference Chain (VIC) framework, a novel approach that constructs reasoning chains using textual context alone before introducing visual input, effectively reducing cross-modal biases and enhancing multimodal reasoning accuracy. Comprehensive evaluations demonstrate that VIC significantly improves zero-shot performance across various vision-related tasks, mitigating hallucinations while refining the reasoning capabilities of MLLMs.
Type